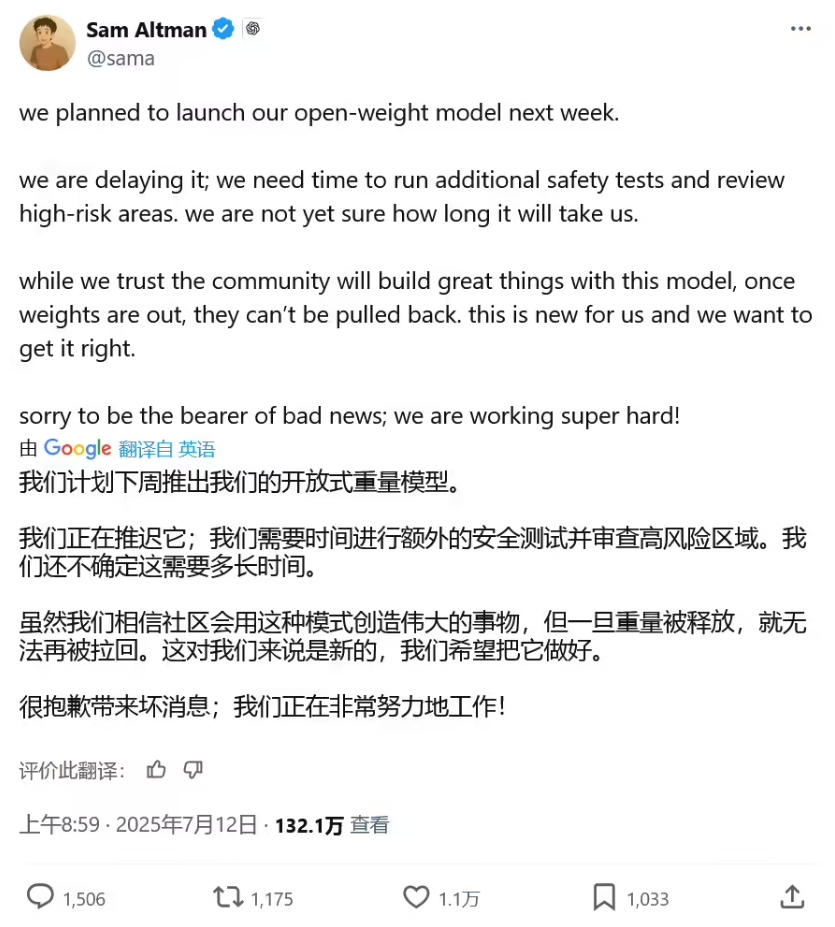
随着人工智能技术的快速发展,机器学习(Machine Learning)和深度学习(Deep Learning)成为当前科技领域的热门话题。尽管两者都属于人工智能的范畴,但它们在定义、原理和应用场景上存在显著差异。本文将从基本概念出发,分析两者的区别,并探讨各自适用的应用场景。
一、机器学习的基本概念与特点
1. 定义
机器学习是一种通过数据训练模型,使其能够从经验中“学习”并做出预测或决策的算法。其核心在于利用大量数据进行模式识别和特征提取,从而实现对未知数据的分类、回归或其他任务。
2. 特点
- 有监督学习:需要标注的数据集来训练模型,例如分类问题中的标签。
- 无监督学习:适用于未标注数据,如聚类分析。
- 半监督学习:结合了有监督和无监督学习的特点。
- 特征工程重要性高:需要人工提取特征以提高模型性能。
二、深度学习的基本概念与特点
1. 定义
深度学习是一种基于人工神经网络的机器学习方法,通过多层非线性变换模拟人脑的工作方式,自动提取数据中的高层次特征。其核心在于“表示学习”(Representation Learning),即模型能够自动从原始数据中提取有意义的特征。
2. 特点
- 层次化特征提取:通过多层网络结构自动提取低级到高级的特征。
- 无需手动特征工程:深度学习能够自动完成特征提取,降低了人工干预的需求。
- 计算资源需求高:需要大量的数据和计算资源来训练复杂的模型。
三、机器学习与深度学习的区别
1. 特点对比
| 特性 | 机器学习 | 深度学习 | |---------------------|-----------------------------------|------------------------------------| | 特征工程 | 需要手动提取特征 | 自动提取特征 | | 模型复杂度 | 模型相对简单,易于解释 | 模型复杂,通常作为“黑箱” | | 数据需求 | 对数据量要求较低,适合小样本数据 | 数据需求较高,尤其需要标注数据 | | 计算资源 | 计算资源需求较低 | 需要大量计算资源和硬件支持 |
2. 应用场景差异
- 机器学习适用场景:
- 分类问题:如垃圾邮件分类、疾病诊断。
- 回归问题:如房价预测、销售趋势分析。
-
聚类问题:如客户分群、市场细分。
-
深度学习适用场景:
- 图像识别:如人脸识别、医学影像分析。
- 自然语言处理(NLP):如机器翻译、情感分析。
- 时间序列分析:如股票预测、天气预报。
四、应用场景总结
1. 传统机器学习的应用
传统机器学习在实际应用中占据重要地位,尤其是在数据量有限的情况下。例如: - 金融领域:信用评分、欺诈检测。 - 医疗领域:基于规则的疾病诊断辅助系统。 - 零售业:客户行为分析、个性化推荐。
2. 深度学习的应用
深度学习在处理复杂任务和大数据场景中表现卓越,例如: - 计算机视觉:自动驾驶中的目标检测、图像分割。 - 自然语言处理:智能客服、机器翻译系统。 - 游戏AI:如AlphaGo、DeepMind在围棋等复杂游戏中的应用。
3. 综合应用
随着技术的发展,机器学习和深度学习的界限逐渐模糊。许多实际项目会结合两者的优点,例如: - 使用传统机器学习进行初步筛选,再通过深度学习模型进行精炼。 - 在图像识别任务中,先用卷积神经网络(CNN)提取特征,再利用支持向量机(SVM)进行分类。
五、总结与展望
机器学习和深度学习各有优劣,选择哪种方法取决于具体的应用场景、数据规模以及业务需求。未来,随着算法的优化和硬件性能的提升,两者的结合应用将更加广泛,为人工智能技术的发展注入新的活力。
本文链接:https://www.7gw.net/3_5343.html
转载请注明文章出处